UPDATE: The tooling originally described here, after much improvement, has been released publicly: https://github.com/manheim/manheim-c7n-tools
This post was originally published to my company’s internal blog platform; I’m publishing it here for the larger Cloud Custodian user community.
At work I’ve spent quite a bit of time over the past few weeks working on our deployment of Capital One’s
cloud custodian (a.k.a. c7n)
for rules and policy enforcement in our AWS accounts, both to replace our aged
Netflix Janitor Monkey
installation and to enable us to expand the cleanup rules we execute and begin
enforcing more granular policies. While we’ve only been running c7n for a few months
(and most of that time in a test only/dry run mode), we’ve already accumulated
29 different policies (mostly Janitor Monkey replacements for tag enforcement and low utilization instance termination)
and are adding new ones rather quickly. Based on interest from colleagues I’d like
to explain a bit about how we manage and deploy Cloud Custodian, and specifically
about how we preprocess our policies to generate the custodian.yml configuration.
Overall Architecture
We currently run all of our Cloud Custodian policies as Lambda functions, taking advantage of c7n’s excellent Lambda support. Each policy currently runs on a schedule (based on CloudWatch Events); we’ve experimented with running policies based on Config rules, Instance state changes and CloudTrail Events, but most of those executed too quickly to prove useful for our needs (specifically tag enforcement policies, as many of our development teams use tooling that defers tagging until significantly after resource creation). In addition to the main Lambda functions that execute the policies, we run a number of other ancillary tools related to Cloud Custodian:
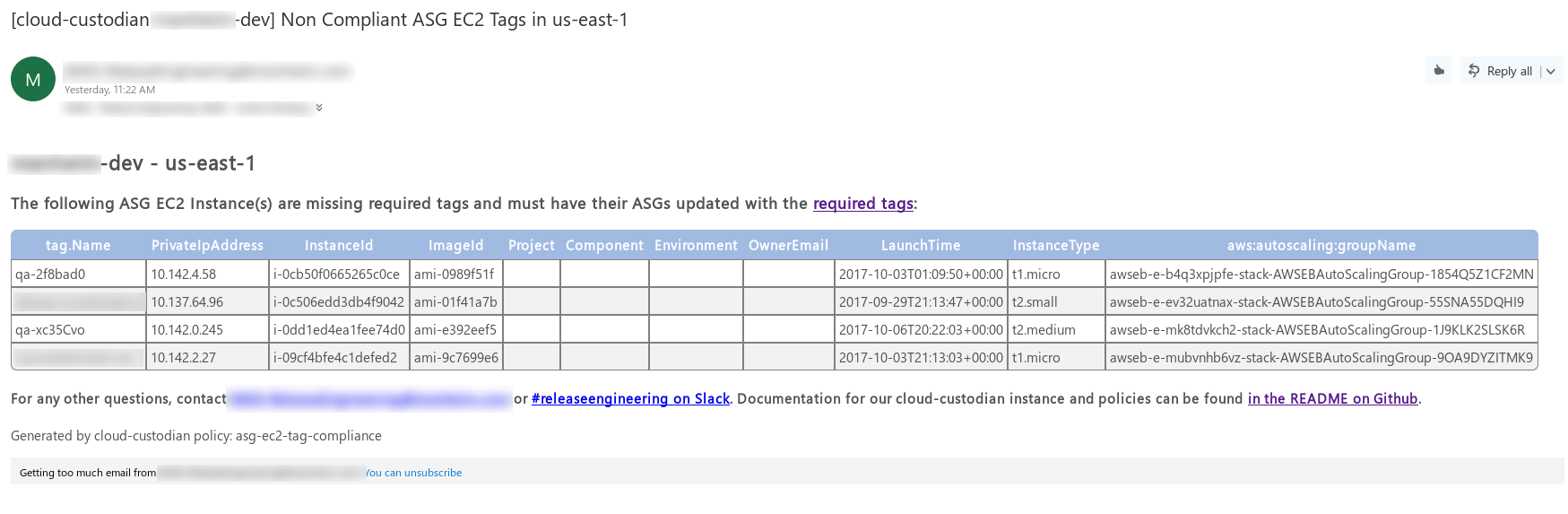
- We use the Custodian Mailer (c7n-mailer)
tool for email notifications, coupled with a customized
email template based on the example
for visually appealing and useful notifications across email clients (like the example below). This also runs as a Lambda
function, and processes notification events that c7n policies push onto an SQS queue.
- We use Splunk as our (new) central logging solution and run a custom Lambda function,
sqs_splunk_lambda, forked fromc7n-mailerbut modified to send cloud-custodian policy run results to Splunk Cloud instead of email. Cloud Custodian’s notify action, which is used to triggerc7n-mailer, works by pushing some JSON data to an SQS queue; this data includes the full details of the policy itself, the resources that the policy matched, and why (what filter(s)) each resource was matched. Our policy preprocessor (see below) adds a notify action to every policy that sends to a specific, separate SQS queue for the Splunk function. The Lambda function processes this queue every five minutes, removes some repetitive and less-important data (to get the message size below 10KB), and then sends the JSON message on to Splunk. This places the full data from every policy execution in Splunk, and allows us to search Splunk for high-level queries like “every EC2 Instance that c7n stopped”, “every resource matched by a specific policy”, or “every action that a specific policy has taken”. - Asynchronous Lambda function executions - such as those triggered by CloudWatch Events - are automatically retried up
to three times if the invocation fails. However, there’s no easy way to tell if all tries of a particular function
invocation failed. errorscan.py
is our solution to this problem. We configure all of our Cloud Custodian policy Lambda functions with a Dead Letter Queue,
a feature of Lambda that pushes a message to a SQS queue if all retries of an invocation failed.
errorscan.pyruns once a day via Jenkins and checks for messages in a single shared Dead Letter Queue (DLQ). If there are any, it uses CloudWatch Logs to associate the queue entry with the Lambda function that failed, and outputs the logs from the failed invocation(s). Theerrorscan.pyscript also examines the Failed and Throttled Invocations metrics in CloudWatch for each function. If there were any entries in the DLQ or failed/throttled invocations metrics beyond a specified threshold, the job will report that information and then fail, triggering a low urgency notification to our on-call engineer. - We store our policies in git, one file per policy, with common default values removed. Our policygen.py script,
explained in detail below, reads the policy files, interpolates our defaults, performs some sanity checking,
and then generates the single
custodian.ymlfile actually used by c7n.
Test and Deployment
We test and deploy our Cloud Custodian infrastructure using a Jenkinsfile. For simplicity of dependencies, most of the stages utilize the Jenkins Docker Workflow plugin and run inside the public python:2-wheezy image and the jobs that manage the infrastructure dependencies run inside the public hashicorp/terraform image. Most of the actual custodian commands are run from a Makefile, which makes it easier to run the same commands from either the Jenkins pipeline or a local development environment.
We follow a pull request GitHub workflow, and only allow merges to the master branch from PRs that have been successfully built by Jenkins. Our pipeline differentiates between builds of the master branch (which triggers deployment) and builds of PRs or other branches (which are test/dry run only).
The steps in the pipeline are as follows:
- Terraform - run a
terraform applyfor master, or aterraform planfor non-master. This uses terraform to manage the required infrastructure for c7n, namely the CloudWatch Log Group for the c7n lambda functions, the s3 bucket for the c7n output, the IAM Role that the c7n functions execute with, and the SQS queues for the mailer, splunk log shipper, and the dead letter queue. - virtualenv - Setup a new Python virtualenv in the Docker container for the following steps, and copy the current directory
(git clone / Jenkins workspace) to
/appin the container. We do the latter because Jenkins runs as a normal user but the public Python docker container prefers to run as root (0:0). To prevent problems, we copy the Jenkins workspace to/appin the container, run what we need to, and then copy any desired output back to the workspace andchownit to Jenkins’ user and group when finished. - tox - Install tox in the virtualenv; we use this to run pytest unit tests for our custom code in subsequent steps.
- policygen tests - Run unit tests for our policygen.py script.
- sqs_splunk_lambda tests - Run unit tests for our
sqs_splunk_lambdaSplunk log shipper code. - Validate - Install dependencies for c7n, generate our
custodian.ymlfile usingpolicygen.py, and then runcustodian validateon the resulting file. This step also generates thepolicies.rstfile containing a table of our current policy names and comments/descriptions (which we include in our internal Sphinx-built documentation), and copies bothcustodian.ymlandpolicies.rstback to the Jenkins workspace for archiving in the job history. - mugc dry run - Cloud Custodian deploys its Lambda functions via a reusable Lambda management library, c7n.mu, and we use its garbage collection tool, mugc.py, to clean up the Lambda functions and CloudWatch Events for policies we’ve deleted. In this step, we do a dry run of the garbage collection script.
- custodian dry run - This performs a
custodiandry run as a final check for our policies, copies the dry-run results/output back to the Jenkins workspace, and archives it in the job history. - Run - For builds of the master branch, we do the actual
mugc.pygarbage collection of old Lambdas/Events, do the actualcustodianrun to provision our c7n Lambda functions, and provision thec7n_mailerLambda function. For non-master branches, we only install the mailer’s dependencies (sanity check) and print our mailer config file to STDOUT. - sqs_splunk_lambda - For builds of master, we install our
sqs_splunk_lambdacode and provision its Lambda function. For builds other than master, we runsqs_splunk_lambda --validateto validate its configuration file. This step is run in aVaultBuildWrapper, as it securely retrieves Splunk credentials from our HashiCorp Vault instance. - Build Docs - We run a Sphinx build of our documentation, which is mostly static content but also includes the generated list of our policies from step 6.
- Publish Docs - For builds of master, we push the HTML documentation built in the last step to the
gh-pagesbranch for serving via GitHub Pages. - Job DSL for Monitoring Job - For builds of master, we run
Job DSL to create or update a persistent Jenkins job
(outside the pipeline) that runs
errorscan.pyonce a day and notifies us if any Lambda function errors were found.
We also have shell scripts provided for testing changes and doing dry runs locally, which use the same Docker images and Makefile as the Jenkins-based build.
Policy Preprocessing
Our policygen.py script is responsible for reading in the directory of per-policy YAML files,
performing some sanity checks on them, interpolating defaults from a policies/defaults.yml file,
and then writing out the single custodian.yml that Cloud Custodian actually runs. The overall program flow is as follows:
- Read in all
.ymlfiles from thepolicies/directory; build a dict of policy names to the policy contents, deserialized from YAML into native Python data structures. For each policy file, ensure that the filename without the extension (i.e. the basename) matches the value of the “name” key in the policy YAML; raise an exception if any policies do not have a filename that matches their policy name. - Remove the
defaultspolicy from that dict, and store it separately for later use. - Iterate over all policies in the dict, lexicographically by policy name; for each of them, interpolate our defaults into the policy and append the result to a “policies” list. See below for details of the defaults interpolation process.
- Generate “cleanup” policies and append them to the list. This step is a holdover from before cloud-custodian had the mugc Lambda cleanup tool but we still use it; this uses the names of all current policies to generate two policies that identify Lambda functions and CloudWatch Event Targets, respectively, that were provisioned by Cloud Custodian for policies that no longer exist. The resulting policies run once per day, and email us if there are any “orphaned” Cloud Custodian functions or rules.
- Run a series of sanity and safety checks on the generated policies (see “Policy Sanity Checks”, below, for more information).
- Write the final
custodian.ymlthat will be used by Cloud Custodian, containing all of our final policies. - Write a
policies.rstfile that will be incorporated into our Sphinx-generated HTML documentation site. This file contains a table with one row per policy for all of our policies; the first column is the policy name as a HTML link to the policy.ymlfile in the git repository, and the second column is the text of the policy’scommentorcommentsfield.
Interpolating Defaults into Policies
The most important part of policygen.py is the interpolation of defaults into policies.
When we originally deployed Cloud Custodian in our test environment, we noticed that our
policies had two large blocks that were almost identical across all policies: the mode
configuration telling Cloud Custodian to deploy the policies as Lambda functions triggered
by periodic CloudWatch Events rules, and the notification action that we use for email
notifications. This was the genesis of policygen.py; we moved these common policy
sections to a defaults.yml file, and wrote policygen.py to perform intelligent
merging of the defaults with each policy file, allowing us to override defaults in the
individual policies but still keep some mandatory settings.
Our defaults.yml file currently looks like this:
# IMPORTANT NOTE: **ALL** policies will have an additional notification action for the Splunk SQS queue
mode:
type: periodic
# This will trigger our rules at 15:20 UTC (11:20 EDT / 10:20 EST)
# it might be better to spread them out over time a bit, but right now our
# main concern is ensuring that policies run during work hours.
schedule: 'cron(20 15 * * ? *)'
timeout: 300
execution-options:
log_group: /cloud-custodian/123456789012/us-east-1
output_dir: 's3://SOME-BUCKET-NAME/logs'
dead_letter_config:
TargetArn: arn:aws:sqs:us-east-1:123456789012:cloud-custodian-123456789012-deadletter
role: arn:aws:iam::123456789012:role/cloud-custodian-123456789012
tags:
Project: cloud-custodian
Environment: dev
OwnerEmail: us@example.com
actions:
- type: notify
questions_email: us@example.com
questions_slack: ourChannelName
template: redefault.html
to:
- resource-owner
- us@example.com
- awsusers@example.com
transport:
type: sqs
queue: 'https://sqs.us-east-1.amazonaws.com/123456789012/cloud-custodian-123456789012'
This provides us with our default execution mode (Lambda function triggered once a day at a defined time via CloudWatch Events) and its configuration options (mainly, the IAM Role used for execution, the Dead Letter Queue, CloudWatch Log Group, and S3 output configuration for policy results), as well as our default email notification configuration using SQS to c7n-mailer.
All of these options can be overridden in individual policies intelligently; a simple example policy that emails us about any VPC Peering Connections in a state other than “active” would look like:
# REMINDER: defaults.yml will be merged in to this. See the README.
name: inactive-vpc-peers
comment: Notify RE of any VPC Peering Connections not in Active state (i.e. pending-acceptance, failed, etc.)
resource: peering-connection
filters:
# Peering Connection not in "active" state
- type: value
key: Status.Code
op: ne
value: "active"
actions:
- type: notify
violation_desc: The following VPC Peering Connections are in a state other than "active"
action_desc: likely need to be accepted, deleted, or investigated.
subject: '[cloud-custodian {{ account }}] VPC Peering Connections not in Active state {{ region }}'
to:
- us@example.com
This policy automatically inherits all of the mode defaults configuration and the notify
action is merged with the defaults; the resulting generated policy will combine all of the keys
in the defaults notification action and the policy notification action, with the exception of the
to block where the defaults are overridden by the policy.
The actual process of merging the policy and defaults is a recursive deep merge of the dicts, merging
the individual policy over a copy of the defaults, with special logic for lists and
type: notify actions. Overall, the procedure is:
- We start with policies/defaults.yml as a base, and layer the policy-specific config on top of it.
- We merge recursively (i.e. deep merging).
- Keys from the policy overwrite identical keys in the defaults; the policy-specific config always wins over the defaults.
- In the case of lists (i.e. the
actionslist), the end result includes all elements that are simple data types (i.e. strings). For dict items in lists, we look at the value of thetypeelement; if both the policy and the defaults lists have dicts with the sametype, we merge them together, with the policy overwriting the defaults. Defaults dicts without a matchingtypein the policy will always be in the final result, except foractionswith a type ofnotify; policies that do not have atype: notifyaction will not have one added. This allows us to set defaults for dicts embedded in lists, like thetype: notifyaction. - When finished merging, add a notification action to every policy that pushes to the Splunk queue, which is handled by our sqs_splunk_lambda code.
To merge the two dicts together, we begin with a copy of the defaults and then iterate over all of the items in the policy as key/value pairs, updating the defaults as we go to build the final policy:
- If the key from the policy-specific config isn’t in the defaults, we add the key and value and move on. Otherwise;
- If the value is a list, we use special list merging logic (see below) and update with the result of the list merge.
- If the value is another dict, we call the same function recursively and update with its result.
- If the value isn’t a list or dict, we assume it to be a simple type (string, int, etc.) and overwrite the default value with the one specified in the policy-specific configuration.
- The end result of this is returned.
List merging is somewhat special, to let us set defaults for actions:
- We begin with the policy itself as the base list, instead of the defaults.
- Any non-dict items in defaults that aren’t in the policy are appended to the policy list.
- Any dict items in the policy list with a
typekey/value pair that matches one of the dict items in the defaults list, will have additional key/value pairs added from the defaults dict. - Any defaults dicts not handled under the previous condition will be appended to the result, with the exception of a
type: notifydict in the['actions']path.
Policy Sanity Checks
Before writing out the final custodian.yml configuration, each policy is run through a sanity/safety checking
function. The function is written to be easily extendable to add new policy checks (written in Python), but currently
only has two checks:
-
Ensure that any
marked-for-opfilters come first in the filter list. When we originally deployed Cloud Custodian, one of our policies had amarked-for-opfilter (which allows Cloud Custodian to take action on a resource that was specifically tagged for delayed action in the future) accidentally nested under anorclause in the policy YAML (which was unfortunately easy to do, as it only required accidentally indenting the block two extra spaces). This resulted in the policy taking action immediately instead of a week later, which could have been catastrophic (luckily the action in this case was benign). To prevent this from happening again, our checks ensure thatmarked-for-opfilters, if present, always come at the beginning of the list of filters. -
Ensure that any policies with
mark-for-opactions also filter out resources that already have the cooresponding tag, to prevent policies from constantly marking for a future date and never taking action.
Conclusion
We’re still in the process of expanding our Cloud Custodian deployment; right now we’re only running it in one region of one non-production account, but that one region contains the vast majority of our infrastructure. We’ll be expanding to other regions and then production accounts in the next few weeks, and that will require changing some portions of our configuration, management, and policy generation code to compensate. So far we’ve seen good results with using Cloud Custodian to enforce tagging and cost-reduction rules, such as terminating instances that have been idle for a long time. We hope to continue extending the role that Cloud Custodian plays in cost reduction, and also expand into enforcing more security and “housekeeping” policies.
Source Code
The repository that we use for this is private, but I’ve been given permission to publish some of the generic portions of the related code. I don’t really have an established method of publishing source code that I don’t “own” and am not the authoritative source for, so I’m just going to leave it inline here…
redefault.html.j2 Email Template
<!DOCTYPE html>
<html lang="en">
{#
Sample Policy that can be used with this template:
Additional parameters can be passed in from the policy - i.e. action_desc, violation_desc
- name: delete-unencrypted-ec2
comments: Identifies EC2 instances with unencrypted EBS volumes and terminates them.
resource: ec2
filters:
- type: ebs
key: Encrypted
value: false
actions:
- terminate
- type: notify
template: redefault.html
subject: "[cloud-custodian {{ account }}] Unencrypted EC2 Instances DELETED in {{ region }}"
violation_desc: "The following EC2(s) are not encrypted"
action_desc: have been terminated per <a href="https://docs.example.com/aws-policies">standard policy</a>
questions_email: you@example.com
questions_slack: YourSlackChannel
to:
- resource-owner
- example@yourdomain.com
transport:
type: sqs
queue: https://sqs.us-east-1.amazonaws.com/12345678910/custodian-sqs-queue
#}
{# You can set any mandatory tags here, and they will be formatted/outputted in the message #}
{% set requiredTags = ['Project','Component','Environment','OwnerEmail','aws:autoscaling:groupName'] %}
{# The macros below format some resource attributes for better presentation #}
{% macro getTag(resource, tagKey) -%}
{% if resource.get('Tags') %}
{% for t in resource.get('Tags') %}
{% if t.get('Key')|lower == tagKey|lower %}
{{ t.get('Value') }}
{% endif %}
{% endfor %}
{% endif %}
{%- endmacro %}
{% macro extractList(resource, column) -%}
{% for p in resource.get(column) %}
{{ p }},
{% endfor %}
{%- endmacro %}
{% macro columnHeading(columnNames, tableWidth) -%}
<table style="width: {{ tableWidth }}; border-spacing: 0px; box-shadow: 5px 5px 5px grey; border-collapse:separate; border-radius: 7px;">
<tr>
{% for columnName in columnNames %}
{% set thstyle = "background: #a1bae2; color: white; border: 1px solid #a1bae2; text-align: center; padding: 5px;" %}
{% if loop.index == 1 %}
<th style="{{ thstyle }} border-top-left-radius: 7px;">{{ columnName }}</th>
{% elif loop.index == columnNames|length %}
<th style="{{ thstyle }} border-top-right-radius: 7px;">{{ columnName }}</th>
{% else %}
<th style="{{ thstyle }}">{{ columnName }}</th>
{% endif %}
{% endfor %}
</tr>
{%- endmacro %}
{# This macro handles dotted column names, to retrieve nested dictionary values #}
{% macro columnValue(resource, columnName) %}
{%- if '.' not in columnName %}
{{ resource.get(columnName) }}
{%- else %}
{{ columnValue(resource[columnName[:columnName.index('.')]], columnName[columnName.index('.')+1:]) }}
{%- endif %}
{%- endmacro %}
{# This macro creates a row in the table #}
{% macro tableRow(resource, columnNames, loop_idx, res_len) %}
{% if loop_idx % 2 == 0 %}
<tr style="background-color: #f2f2f2;">
{% else %}
<tr>
{% endif %}
{% for columnName in columnNames %}
{% set tdpart = "border: 1px solid grey; padding: 4px;" %}
{% if loop_idx == res_len %}
{# last row in table #}
{% if loop.index == 1 %}
{# first td in row #}
{% set tdpart = "%s border-bottom-left-radius: 7px;" % tdpart %}
{% elif loop.index == columnNames|length %}
{# last td in row #}
{% set tdpart = "%s border-bottom-right-radius: 7px;" % tdpart %}
{% endif %}
{% endif %}
{% if columnName in requiredTags %}
<td style="{{ tdpart }}">{{ getTag(resource,columnName) }}</td>
{% elif columnName == 'tag.Name' %}
<td style="{{ tdpart }}">{{ getTag(resource,'Name') }}</td>
{% elif columnName == 'InstanceCount' %}
<td align="center" style="{{ tdpart }}">{{ resource['Instances'] | length }}</td>
{% elif columnName == 'VolumeConsumedReadWriteOps' %}
<td style="{{ tdpart }}">{{ resource['c7n.metrics']['AWS/EBS.VolumeConsumedReadWriteOps.Maximum'][0]['Maximum'] }}</td>
{% elif columnName == 'PublicIp' %}
<td style="{{ tdpart }}">{{ resource['NetworkInterfaces'][0].get('Association')['PublicIp'] }}</td>
{% else %}
<td style="{{ tdpart }}">{{ columnValue(resource, columnName) }}</td>
{% endif %}
{% endfor %}
</tr>
{%- endmacro %}
{# The macro below creates the table:
Formatting can be dependent on the column names that are passed in
#}
{% macro columnData(resources, columnNames) -%}
{% set len = resources|length %}
{% for resource in resources %}
{% set idx = loop.index %}
{{ tableRow(resource, columnNames, idx, len) }}
{% endfor %}
</table>
{%- endmacro %}
{# Main #}
{% macro createTable(columnNames, resources, tableWidth) %}
{{ columnHeading(columnNames, tableWidth) }}
{{ columnData(resources, columnNames) }}
{%- endmacro %}
<head>
<title>Cloud Custodian Notification - {{ "%s - %s" | format(account,region) }}</title>
</head>
<body>
<h2><font color="#505151">{{ "%s - %s" | format(account,region) }} cloud custodian (<a href="https://github.com/example/custodian-config/">docs</a>)</h2>
{% if action['action_desc'] %}
<h3> {{ action['violation_desc'] }} and <strong>{{ action['action_desc'] }}</strong>:</h3>
{% else %}
<h3> {{ action['violation_desc'] }}:</h3>
{% endif %}
{# Below, notifications for any resource-type can be formatted with specific columns #}
{% if policy['resource'] == "ami" %}
{% set columnNames = ['Name','ImageId','CreationDate'] %}
{{ createTable(columnNames, resources, '60') }}
{% elif policy['resource'] == "app-elb" %}
{% set columnNames = ['LoadBalancerName','CreatedTime','Project','Component','Environment','OwnerEmail'] %}
{{ createTable(columnNames, resources, '80') }}
{% elif policy['resource'] == "asg" %}
{% if resources[0]['Invalid'] is defined %}
{% set columnNames = ['AutoScalingGroupName','InstanceCount','Invalid'] %}
{% else %}
{% set columnNames = ['AutoScalingGroupName','InstanceCount','Project','Component','Environment','OwnerEmail'] %}
{% endif %}
{{ createTable(columnNames, resources, '60') }}
{% elif policy['resource'] == "cache-cluster" %}
{% set columnNames = ['CacheClusterId','CacheClusterCreateTime','CacheClusterStatus','Project','Component','Environment','OwnerEmail'] %}
{{ createTable(columnNames, resources, '80') }}
{% elif policy['resource'] == "cache-snapshot" %}
{% set columnNames = ['SnapshotName','CacheClusterId','SnapshotSource','Project','Component','Environment','OwnerEmail'] %}
{{ createTable(columnNames, resources, '80') }}
{% elif policy['resource'] == "cfn" %}
{% set columnNames = ['StackName'] %}
{{ createTable(columnNames, resources, '50') }}
{% elif policy['resource'] == "cloudsearch" %}
{% set columnNames = ['DomainName'] %}
{{ createTable(columnNames, resources, '50') }}
{% elif policy['resource'] == "ebs" %}
{% set columnNames = ['VolumeId','CreateTime','State','Project','Component','Environment','OwnerEmail'] %}
{{ createTable(columnNames, resources, '50') }}
{% elif policy['resource'] == "ebs-snapshot" %}
{% set columnNames = ['SnapshotId','StartTime','Project','Component','Environment','OwnerEmail'] %}
{{ createTable(columnNames, resources, '80') }}
{% elif policy['resource'] == "ec2" %}
{% if resources[0]['MatchedFilters'] == ['PublicIpAddress'] %}
{% set columnNames = ['tag.Name','PublicIp','InstanceId','ImageId','Project','Component','Environment','OwnerEmail','LaunchTime','InstanceType','aws:autoscaling:groupName'] %}
{% else %}
{% set columnNames = ['tag.Name','PrivateIpAddress','InstanceId','ImageId','Project','Component','Environment','OwnerEmail','LaunchTime','InstanceType','aws:autoscaling:groupName'] %}
{% endif %}
{{ createTable(columnNames, resources, '80') }}
{% elif policy['resource'] == "efs" %}
{% set columnNames = ['CreationToken','CreationTime','FileSystemId','OwnerId'] %}
{{ createTable(columnNames, resources, '50') }}
{% elif policy['resource'] == "elasticsearch" %}
{% set columnNames = ['DomainName','Endpoint'] %}
{{ createTable(columnNames, resources, '50') }}
{% elif policy['resource'] == "elb" %}
{% set columnNames = ['LoadBalancerName','InstanceCount','AvailabilityZones','Project','Component','Environment','OwnerEmail'] %}
{{ createTable(columnNames, resources, '80') }}
{% elif policy['resource'] == "emr" %}
{% set columnNames = ['Id','EmrState'] %}
{{ createTable(columnNames, resources, '50') }}
{% elif policy['resource'] == "kinesis" %}
{% set columnNames = ['KinesisName'] %}
{{ createTable(columnNames, resources, '50') }}
{% elif policy['resource'] == "launch-config" %}
{% set columnNames = ['LaunchConfigurationName'] %}
{{ createTable(columnNames, resources, '30') }}
{% elif policy['resource'] == "log-group" %}
{% set columnNames = ['logGroupName'] %}
{{ createTable(columnNames, resources, '30') }}
{% elif policy['resource'] == "peering-connection" %}
{% set columnNames = ['VpcPeeringConnectionId', 'Status.Code', 'Status.Message', 'ExpirationTime', 'RequesterVpcInfo.OwnerId', 'RequesterVpcInfo.VpcId', 'RequesterVpcInfo.CidrBlock', 'AccepterVpcInfo.OwnerId', 'AccepterVpcInfo.VpcId', 'AccepterVpcInfo.CidrBlock'] %}
{{ createTable(columnNames, resources, '80') }}
{% elif policy['resource'] == "rds" %}
{% set columnNames = ['DBInstanceIdentifier','DBName','Project','Component','Environment','OwnerEmail','Engine','DBInstanceClass','MultiAZ','PubliclyAccessible'] %}
{{ createTable(columnNames, resources, '80') }}
{% elif policy['resource'] == "rds-snapshot" %}
{% set columnNames = ['DBSnapshotIdentifier','SnapshotCreateTime','DBInstanceIdentifier','SnapshotType','Project','Component','Environment','OwnerEmail'] %}
{{ createTable(columnNames, resources, '80') }}
{% elif policy['resource'] == "redshift" %}
{% if resources[0]['PubliclyAccessible'] == true or resources[0]['Encrypted'] == false %}
{% set columnNames = ['ClusterIdentifier','NodeCount','PubliclyAccessible','Encrypted'] %}
{% else %}
{% set columnNames = ['ClusterIdentifier','NodeCount','Project','Component','Environment','OwnerEmail'] %}
{% endif %}
{{ createTable(columnNames, resources, '80') }}
{% elif policy['resource'] == "redshift-snapshot" %}
{% set columnNames = ['SnapshotIdentifier','DBName','Project','Component','Environment','OwnerEmail'] %}
{{ createTable(columnNames, resources, '80') }}
{% elif policy['resource'] == "s3" %}
{% if resources[0]['GlobalPermissions'] is defined %}
{% set columnNames = ['Name','GlobalPermissions'] %}
{% else %}
{% set columnNames = ['Name','Project','Component','Environment','OwnerEmail'] %}
{% endif %}
{{ createTable(columnNames, resources, '80') }}
{% elif policy['resource'] == "security-group" %}
{% set columnNames = ['GroupName','tag.Name','GroupId','VpcId'] %}
{{ createTable(columnNames, resources, '80') }}
{% elif policy['resource'] == "simpledb" %}
{% set columnNames = ['DomainName'] %}
{{ createTable(columnNames, resources, '60') }}
{# If no special formatting is defined for a resource type, all attributes will be formatted in the email #}
{% else %}
{% set columnNames = resources[0].keys() %}
{{ createTable(columnNames, resources, '100') }}
{% endif %}
<h4>
For any other questions, contact <a href="mailto:{{ action['questions_email'] }}">{{ action['questions_email'] }}</a>
or <a href="https://example.slack.com/messages/{{ action['questions_slack'] }}/">#{{ action['questions_slack'] }} on Slack</a>.
Documentation for our cloud-custodian instance and policies can be found at: <a href="https://github.com/example/custodian-config/">https://github.com/example/custodian-config/</a>.
</h4>
<p>Generated by cloud-custodian policy: {{ policy['name'] }} in {{ account }} {{ region }}</p>
</body>
</html>
Jenkinsfile
#!/usr/bin/env groovy
node {
deleteDir()
checkout scm
wrap([$class: 'AnsiColorBuildWrapper', 'colorMapName': 'XTerm', 'defaultFg': 1, 'defaultBg': 2]) {
wrap([$class: 'TimestamperBuildWrapper']) {
def environment = docker.image('python:2-wheezy')
def tfimg = docker.image('hashicorp/terraform:0.9.6')
def gitUrl = sh(script: "git config remote.origin.url", returnStdout: true).trim()
def gitCommit = sh(script: "git rev-parse HEAD", returnStdout: true).trim()
def repo = 'github.com/example/custodian-config'
try {
tfimg.inside {
if (env.BRANCH_NAME == 'master') {
stage('Terraform Apply') {
sh "cd terraform && ./run.sh apply"
}
} else {
stage('Terraform Plan') {
sh "cd terraform && ./run.sh plan"
}
}
} // tfimg
// run as user 0 group 0 - see comment in Setup Virtualenv stage
environment.inside('-u 0:0') {
withEnv(["GIT_COMMIT=${gitCommit}"]) {
stage('Setup Virtualenv') {
/*
* If we run the container as 1000:1000 (which Jenkins will do by
* default), we can't pip install from a git URL in the container,
* because we're running as a user not present in /etc/passwd. But
* running as 0:0 has the side effect that any files we create
* in `pwd` (the workspace, mounted RW into the container) will be
* owned 0:0 (even on the host)... which means deleteDir() will fail
* with permissions errors. The simple solution is to not touch
* anything in the workspace at all; copy it to a path that exists
* only in the container and mess with it there.
*/
sh "mkdir /app && cp -a . /app && cd /app && virtualenv --no-site-packages -p python2.7 ."
}
stage('Install tox') {
sh "cd /app && . bin/activate && pip install tox"
}
stage('Test policygen.py') {
sh "cd /app && . bin/activate && tox"
}
stage('Test sqs_splunk_lambda') {
sh "cd /app/sqs_splunk_lambda && . ../bin/activate && tox"
}
stage('Validate') {
sh "cd /app && make validate && cat custodian.yml && cat policies.rst"
sh "cp /app/custodian.yml . && cp /app/policies.rst ."
archiveArtifacts artifacts: "custodian.yml,policies.rst", allowEmptyArchive: true
}
stage('Lambda Garbage Collection Dry Run') {
sh "cd /app && make mugc-dryrun"
}
stage('Dry Run') {
sh "cd /app && make dryrun"
sh "cp -a /app/dryrun . && chown -R 1000:1000 ."
archiveArtifacts artifacts: "custodian.yml,policies.rst,dryrun/**/*", allowEmptyArchive: true
}
if (env.BRANCH_NAME == 'master') {
stage('Lambda Garbage Collection') {
sh "cd /app && make mugc"
}
stage('Install and Provision Mailer') {
sh "cd /app && make run mailer"
}
} else {
stage('Install Mailer') {
// not master - install deps but don't run mailer
sh "cd /app && make mailerdeps && cat mailer.yml"
}
}
// sqs_splunk_lambda needs Vault creds
def secrets = [
[
$class: 'VaultSecret',
path: 'some/path',
secretValues: [
// redacted; get some secrets, and set them in the environment
]
]
]
wrap([$class: 'VaultBuildWrapper', vaultSecrets: secrets]) {
if (env.BRANCH_NAME == 'master') {
stage('Install and provision sqs_splunk_lambda') {
sh "cd /app/sqs_splunk_lambda && . ../bin/activate && python setup.py develop"
sh "cd /app && . bin/activate && sqs_splunk_lambda -c sqs_splunk_lambda.yml --update-lambda"
}
} else {
stage('Install and verify sqs_splunk_lambda') {
sh "cd /app/sqs_splunk_lambda && . ../bin/activate && python setup.py develop"
sh "cd /app && . bin/activate && sqs_splunk_lambda -c sqs_splunk_lambda.yml --validate"
}
}
} // wrap
stage('Build Docs') {
sh "cd /app && make docs"
}
if (env.BRANCH_NAME == 'master') {
stage('Publish Docs') {
withCredentials([usernamePassword(credentialsId: 'SomeID', passwordVariable: 'GIT_PASS', usernameVariable: 'GIT_USER')]) {
sh("""
cd /app/docs/_build/
git init
git config user.name "jenkins"
git config user.email "jenkins@example.com"
git remote add origin git@${repo}
git checkout -b gh-pages
git add --all
git commit -m "docs published by ${env.BUILD_URL}"
git push -f "https://${env.GIT_PASS}@${repo}" HEAD:gh-pages
""")
} // withCredentials
} // stage('Publish Docs')
stage('Apply Job DSL for errorscan.py cron-based Jenkins job') {
build job: 'SeedJob', parameters: [
string(name: 'APP_NAME', value: 'cloud-custodian'),
string(name: 'APP_REPO', value: 'git@github.com:example/custodian-config'),
string(name: 'PATH_TO_DSL', value: 'config/pipeline.groovy'),
string(name: 'APP_REPO_BRANCH', value: 'master')
]
} // stage
} // if env.BRANCH_NAME == 'master'
} // withEnv
} //environment
currentBuild.result = 'SUCCESS'
} catch(Exception ex) {
echo "Caught exception: ${ex.toString()}"
currentBuild.result = 'FAILURE'
throw ex
} finally {
echo "Build result: ${currentBuild.result}"
if (currentBuild.result == 'SUCCESS') {
slackSend(color: 'good', message: "SUCCESS: ${env.JOB_NAME} <${env.BUILD_URL}|build ${env.BUILD_NUMBER}>")
} else {
slackSend(color: 'danger', message: "FAILED: ${env.JOB_NAME} <${env.BUILD_URL}|build ${env.BUILD_NUMBER}>")
}
}
} // wrap TimestamperBuildWrapper
} // wrap AnsiColorBuildWrapper
}
Makefile
.PHONY: docs clean
PROJECT=$(shell grep "project" terraform/terraform.tfvars | cut -d= -f2 | tr -d '[[="=]],[[:space:]]')
ENVIRONMENT=$(shell grep "environment" terraform/terraform.tfvars | cut -d= -f2 | tr -d '[[="=]],[[:space:]]')
ACCOUNT_ID=$(shell aws sts get-caller-identity --region=$(REGION) --output text --query 'Account')
BUCKET=s3://$(PROJECT)-$(ACCOUNT_ID)
REGION=us-east-1
MARKDOWN = pandoc --from markdown_github --to html --standalone
INSTALL_REPO=git+https://github.com/capitalone/cloud-custodian.git
INSTALL_REF=0.8.26.0
virtualenv:
if [ ! -e "./bin/activate_this.py" ] ; then virtualenv --clear .; fi
deps: virtualenv
PYTHONPATH=. ; . ./bin/activate && \
pip install -e "$(INSTALL_REPO)@$(INSTALL_REF)#egg=c7n"
mailerdeps: deps
PYTHONPATH=. ; . ./bin/activate && \
pip install -r src/c7n/tools/c7n_mailer/requirements.txt && \
cd src/c7n/tools/c7n_mailer && \
python setup.py develop && \
cd ../../../../
cp templates/* src/c7n/tools/c7n_mailer/msg-templates/
clean: clean-build clean-pyc clean-test
clean-build:
rm -fr build/
rm -fr dist/
rm -fr .eggs/
find . -name '*.egg-info' -exec rm -rf {} +
find . -name '*.egg' -exec rm -rf {} +
clean-pyc:
find . -name '*.pyc' -exec rm -f {} +
find . -name '*.pyo' -exec rm -f {} +
find . -name '*~' -exec rm -f {} +
find . -name '__pycache__' -exec rm -fr {} +
clean-test:
rm -fr .tox/
rm -f .coverage
rm -fr htmlcov/
install: clean
PYTHONPATH=$PYTHONPATH:.:. ; . ./bin/activate && python setup.py install
policies: deps
PYTHONPATH=. ; . ./bin/activate && ./policygen.py
validate: policies
echo "Running custodian in ${ACCOUNT}"
PYTHONPATH=$PYTHONPATH:.:. ; . ./bin/activate && custodian validate -c custodian.yml
dryrun: validate
PYTHONPATH=$PYTHONPATH:.:. ; . ./bin/activate && custodian run --region '$(REGION)' --dryrun -v -s dryrun -c custodian.yml --cache '/tmp/.cache/cloud-custodian.cache'
run: validate
PYTHONPATH=$PYTHONPATH:.:. ; . ./bin/activate && custodian run --region '$(REGION)' --metrics -v -s $(BUCKET)/logs --log-group=/cloud-custodian/$(ACCOUNT_ID)/$(REGION) -c custodian.yml --cache '/tmp/.cache/cloud-custodian.cache'
mugc: validate
PYTHONPATH=$PYTHONPATH:.:. ; . ./bin/activate && python src/c7n/tools/ops/mugc.py -v -r '$(REGION)' -c custodian.yml
mugc-dryrun: validate
PYTHONPATH=$PYTHONPATH:.:. ; . ./bin/activate && python src/c7n/tools/ops/mugc.py -v --dryrun -r '$(REGION)' -c custodian.yml
config:
@echo $(PROJECT)
@echo $(ENVIRONMENT)
@echo $(BUCKET)
mailer: mailerdeps
PYTHONPATH=$PYTHONPATH:.:. ; . ./bin/activate && c7n-mailer -c mailer.yml --update-lambda
docdeps: virtualenv
PYTHONPATH=. ; . ./bin/activate && \
pip install sphinx==1.6.4 sphinx_rtd_theme==0.2.4
docs: docdeps
if [ -e "./docs/_build" ] ; then rm -Rf docs/_build; fi
PYTHONPATH=. ; . ./bin/activate && \
sphinx-build -W docs/source docs/_build -b dirhtml
policygen.py
#!/usr/bin/env python
"""
There are unit tests for this script; see `test_policygen.py`.
If you want to add a sanity/safety test to run against all policies during
the Jenkins build, see ``PolicyGen._check_policies()``.
"""
import sys
import os
import re
from copy import deepcopy
from collections import defaultdict
from datetime import datetime
from tabulate import tabulate
import yaml
from yaml import CSafeLoader
SafeLoader = CSafeLoader
whtspc_re = re.compile('\s+')
REPO_HTML = 'https://github.com/example/custodian-config/'
def strip_doc(func):
"""
Given a function or method reference, return its docstring as one line (with
all newlines removed and all whitespace collapsed).
"""
d = func.__doc__.replace("\n", " ").strip()
return whtspc_re.sub(' ', d)
def timestr():
"""just here to make unit testing simpler"""
return datetime.utcnow().strftime('%Y-%m-%d %H:%M:%S') + ' UTC'
class PolicyGen(object):
# Configuration to send notifications to the splunk SQS queue for
# sqs_splunk_lambda to pick up and send to HEC
SPLUNK_SQS = {
'type': 'notify',
# 'template' and 'to' don't matter, but arerequired keys
'template': 'redefault.html',
'to': ['PlaceholderForSplunkSQSNotify'],
'transport': {
# queue will be filled in by the __init__() method
'type': 'sqs'
}
}
def __init__(self):
# get the Splunk SQS queue URL from the config file
splunk_conf = self._read_file_yaml('sqs_splunk_lambda.yml')
self.SPLUNK_SQS['transport']['queue'] = splunk_conf['queue_url']
def run(self):
policies = self._read_policies()
defaults = policies.pop('defaults')
result = {'policies': []}
for k in sorted(policies.keys()):
result['policies'].append(
self._apply_defaults(defaults, policies[k])
)
print('Generating c7n cleanup policies...')
# add c7n lambda/CW Even cleanup policies
for pol in self._generate_cleanup_policies(
deepcopy(result['policies'])
):
result['policies'].append(self._apply_defaults(defaults, pol))
print('Checking policies for sanity and safety...')
self._check_policies(result['policies'])
print('Writing policies to custodian.yml...')
self._write_file('custodian.yml', yaml.dump(result))
print('Writing policy descriptions to policies.rst...')
self._write_file('policies.rst', self._policy_rst(policies))
def _check_policies(self, policies):
"""
Check all of our policies to ensure that they conform with some rules
and best practices around safety and sanity.
Each policy in ``policies`` is passed through each of the
``self._check_policy_*`` functions (which return a boolean pass/fail).
At the end, all failures are collected. If there are any, SystemExit(1)
is raised.
:param policies: list of policy dictionaries
:type policies: list
:raises: SystemExit(1) if any policies failed checks
"""
policy_checks = []
for x in dir(self):
if x.startswith('_check_policy_') and callable(getattr(self, x)):
policy_checks.append(getattr(self, x))
failures = defaultdict(list)
for pol in policies:
for chk in policy_checks:
if not chk(pol):
failures[pol['name']].append(strip_doc(chk))
if len(failures) > 0:
print('ERROR: Some policies failed sanity/safety checks:')
for pol_name in sorted(failures.keys()):
print(pol_name)
for chk_str in failures[pol_name]:
print("\t" + chk_str)
raise SystemExit(1)
print('OK: All policies passed sanity/safety checks.')
def _check_policy_marked_for_op_first(self, policy):
"""
Policy includes a marked-for-op filter, but it is not the first filter.
"""
if 'filters' not in policy:
return True
if "'type': 'marked-for-op'" not in str(policy['filters']):
return True
try:
if policy['filters'][0].get('type', '') == 'marked-for-op':
return True
except AttributeError:
# first filter isn't even a dict; that's a failure
pass
# fail - first filter isn't marked-for-op
return False
def _check_policy_mark_but_no_tag_filter(self, policy):
"""
Policy performs a mark action, but does not filter out resources already
marked with that tag.
"""
if 'filters' not in policy:
return True
if 'actions' not in policy:
return True
mark_tags = []
for a in policy['actions']:
if not isinstance(a, type({})):
# not a dict, can't be a mark action
continue
if a.get('type', '') != 'mark-for-op':
continue
mark_tags.append(a['tag'])
for t in mark_tags:
tag_filter = {'tag:%s' % t: 'absent'}
if tag_filter not in policy['filters']:
return False
return True
def _generate_cleanup_policies(self, policies):
"""
When c7n is run, it provisions all policies as lambda functions. But if
policies are removed, it doesn't know how to clean them up. See
https://github.com/capitalone/cloud-custodian/issues/48
As a workaround for this, we tag all Lambda funcs created by c7n
with Project: cloud-custodian and a Component tag of the policy name.
This method generates policies that look for cloud-custodian Lambda
functions and CloudWatch Events that aren't in the current list of
policies, and therefore probably need cleanup, and notifies us.
:param policies: list of policy dictionaries
:type policies: list
:return: list of c7n cleanup policies to add
:rtype: list
"""
# base policies that just need filters added
lcleanup = {
'name': 'c7n-cleanup-lambda',
'comment': 'Find and alert on orphaned c7n Lambda functions',
'resource': 'lambda',
'actions': [{
'type': 'notify',
'violation_desc': 'The following cloud-custodian Lambda '
'functions appear to be orphaned',
'action_desc': 'and should probably be deleted',
'subject': '[cloud-custodian {{ account }}] Orphaned '
'cloud-custodian Lambda funcs in {{ region }}',
'to': ['us@example.com']
}],
'filters': [
{'tag:Project': 'cloud-custodian'},
{'tag:Component': 'present'},
# exclude itself...
{
'type': 'value',
'key': 'tag:Component',
'op': 'ne',
'value': 'c7n-cleanup-lambda'
},
{
'type': 'value',
'key': 'tag:Component',
'op': 'ne',
'value': 'c7n-cleanup-cwe'
},
{
'type': 'value',
'key': 'tag:Component',
'op': 'ne',
'value': 'sqs_splunk_lambda'
}
]
}
cwecleanup = {
'name': 'c7n-cleanup-cwe',
'comment': 'Find and alert on orphaned c7n CloudWatch Events',
'resource': 'event-rule',
'actions': [{
'type': 'notify',
'violation_desc': 'The following cloud-custodian CloudWatch '
'Event rules appear to be orphaned',
'action_desc': 'and should probably be deleted',
'subject': '[cloud-custodian {{ account }}] Orphaned '
'cloud-custodian CW Event rules in {{ region }}',
'to': ['us@example.com']
}],
'filters': [
{
'type': 'value',
'key': 'Name',
'op': 'glob',
'value': 'custodian-*'
},
# exclude itself...
{
'type': 'value',
'key': 'Name',
'op': 'ne',
'value': 'custodian-c7n-cleanup-lambda'
},
{
'type': 'value',
'key': 'Name',
'op': 'ne',
'value': 'custodian-c7n-cleanup-cwe'
},
{
'type': 'value',
'key': 'tag:Component',
'op': 'ne',
'value': 'sqs_splunk_lambda'
}
]
}
# add the filters
for p in policies:
name = p['name']
cwecleanup['filters'].append({
'type': 'value',
'key': 'Name',
'op': 'ne',
'value': 'custodian-%s' % name
})
lcleanup['filters'].append({
'type': 'value',
'key': 'tag:Component',
'op': 'ne',
'value': name
})
return [lcleanup, cwecleanup]
def _write_file(self, path, content):
"""write a file - helper to make unit tests simpler"""
with open(path, 'w') as fh:
fh.write(content)
def _apply_defaults(self, defaults, policy):
d = deepcopy(defaults)
conf = self._merge_conf(d, policy, policy['name'], [])
# set Lambda func 'Component' tag to the policy name
if conf['mode']['type'] == 'periodic':
if 'tags' not in conf['mode']:
conf['mode']['tags'] = {}
conf['mode']['tags']['Component'] = policy['name']
if 'actions' not in conf:
conf['actions'] = []
conf['actions'].append(deepcopy(self.SPLUNK_SQS))
return conf
def _merge_conf(self, base, update, policy_name, path):
"""merge update into base"""
for k, v in update.items():
kpath = path + [k]
if (
kpath == ['mode'] and v.get('type', 'periodic') != 'periodic'
):
# short-circuit to not alter the 'mode' top-level key on
# policies if it isn't "type: periodic"
base[k] = update[k]
continue
if k not in base:
base[k] = v
continue
if isinstance(v, type([])):
# List / array
base[k] = self._array_merge(base[k], v, policy_name, kpath)
elif isinstance(v, type({})):
# nested dictionary
base[k] = self._merge_conf(base[k], v, policy_name, kpath)
else:
# not a dict or list; probably string or int, etc.
base[k] = v
# remove actions if only specified in base (defaults)
if path == [] and 'actions' in base and not 'actions' in update:
del base['actions']
return base
def _array_merge(self, base, update, policy_name, path):
"""this starts with update, and adds things from base"""
if not isinstance(base, type([])):
print(
'ERROR: policy has an array but defaults does not; cannot merge'
)
raise RuntimeError(
'Policy %s: Cannot array merge non-array from defaults (%s)' % (
policy_name, base
)
)
# find the defaults, by type
def_dicts = {}
for v in base:
if not isinstance(v, type({})):
if v not in update:
update.append(v)
continue
t = v.get('type', None)
if t is None:
raise RuntimeError('Do not know how to handle a defaults '
'dict without a "type" key.')
if t in def_dicts:
raise RuntimeError('Defaults cannot specify multiple dicts '
'with the same "type" in the same array!')
def_dicts[t] = v
# do the updates
for i in update:
if not isinstance(i, type({})):
continue
# else it's a dict, update from defaults if present
t = i.get('type', None)
if t is None:
continue
if t not in def_dicts:
# no defaults for this
continue
for k, v in def_dicts[t].items():
if k not in i:
i[k] = v
del def_dicts[t]
# add any defaults that didn't already exist
for k, v in def_dicts.items():
if path == ['actions'] and k == 'notify':
# Don't add notify actions to policies that don't have them
continue
update.append(v)
return update
def _policy_rst(self, policies):
buildinfo = 'by `%s %s <%s>`_' % (
os.environ.get('JOB_NAME', ''),
os.environ.get('BUILD_NUMBER', ''),
os.environ.get('BUILD_URL', '')
)
commit = os.environ['GIT_COMMIT']
gitlink = '%scommit/%s' % (REPO_HTML, commit)
if buildinfo == 'by ` <>`_':
buildinfo = 'locally'
s = "this page built %s from `%s <%s>`_ at %s\n\n" % (
buildinfo, commit, gitlink, timestr()
)
rows = []
for k in sorted(policies.keys()):
klink = '`%s <%sblob/%s/policies/%s.yml>`_' % (
k, REPO_HTML, commit, k
)
rows.append([klink, self._policy_comment(policies[k])])
s += tabulate(
rows,
headers=['Policy Name', 'Description/Comment'],
tablefmt='grid'
)
return s
def _policy_comment(self, policy):
for k in ['comment', 'comments', 'description']:
if k in policy:
return policy[k].strip()
return 'unknown'
def _read_policies(self):
res = {}
for f in os.listdir('policies/'):
if not f.endswith('.yml'):
continue
name = f.split('.')[0]
y = self._read_file_yaml(os.path.join('policies', f))
res[name] = y
if name != 'defaults' and y.get('name', '') != name:
raise RuntimeError(
'ERROR: Policy file %s contains policy with name "%s".' % (
f, y.get('name', '')
)
)
print('Loaded %d policies: %s' % (len(res), res.keys()))
return res
def _read_file_yaml(self, path):
"""unit test helper - return YAML from file contents"""
with open(path, 'r') as fh:
contents = fh.read()
try:
return yaml.load(contents, Loader=SafeLoader)
except Exception:
sys.stderr.write("Exception loading YAML: %s\n" % path)
raise
if __name__ == "__main__":
PolicyGen().run()
test_policygen.py
#!/usr/bin/env python
"""
Unit tests for policygen.py
To run:
1. ``virtualenv --python=python2.7 . && source bin/activate``
2. ``pip install mock pytest==2.6.4 pytest-cov==1.8.1 coverage==3.7.1``
3. run:
py.test -vv -s --cov-report term-missing --cov-report html \
--cov=policygen.py --cov-config .coveragerc test_policygen.py
"""
import yaml
from mock import patch, call, mock_open, DEFAULT
import pytest
import policygen
import os
REPO_HTML = 'https://github.com/example/custodian-config/'
class TestStripDoc(object):
def test_strip_doc(self):
"""
Testing
the code to strip
whitespace from
docblocks.
"""
expected = 'Testing the code to strip whitespace from docblocks.'
assert policygen.strip_doc(self.test_strip_doc) == expected
class TestApplyDefaults(object):
def setup(self):
with patch('policygen.PolicyGen._read_file_yaml'):
self.cls = policygen.PolicyGen()
self.cls.SPLUNK_SQS = {'Splunk': 'SQS'}
def test_init(self):
with patch('policygen.PolicyGen._read_file_yaml', autospec=True) as m:
m.return_value = {'queue_url': 'myurl'}
cls = policygen.PolicyGen()
assert cls.SPLUNK_SQS['transport']['queue'] == 'myurl'
def test_apply_defaults(self):
defaults = {
'mode': {'type': 'periodic', 'schedule': 'foo'},
'actions': [
{
'type': 'notify',
'questions_email': 'qemail',
'questions_slack': 'qslack',
'transport': {
'queue': 'q',
'type': 'sqs'
},
'to': [
'resource-owner',
'me@example.com'
]
}
]
}
policy = {
'name': 'foo',
'comments': 'my comments',
'resource': 'bar',
'filters': [
{'type': 'baz', 'something': 'else'}
],
'actions': [
'suspend',
{'type': 'notify', 'violation_desc': 'vdesc'}
]
}
expected = {
'name': 'foo',
'comments': 'my comments',
'resource': 'bar',
'filters': [
{'type': 'baz', 'something': 'else'}
],
'mode': {
'type': 'periodic',
'schedule': 'foo',
'tags': {'Component': 'foo'}
},
'actions': [
'suspend',
{
'type': 'notify',
'violation_desc': 'vdesc',
'questions_email': 'qemail',
'questions_slack': 'qslack',
'transport': {
'queue': 'q',
'type': 'sqs'
},
'to': [
'resource-owner',
'me@example.com'
]
},
{'Splunk': 'SQS'}
]
}
assert self.cls._apply_defaults(defaults, policy) == expected
def test_apply_defaults_implicit_mode(self):
defaults = {
'mode': {'type': 'periodic', 'schedule': 'foo'},
'actions': [
{
'type': 'notify',
'questions_email': 'qemail',
'questions_slack': 'qslack',
'transport': {
'queue': 'q',
'type': 'sqs'
},
'to': [
'resource-owner',
'me@example.com'
]
}
]
}
policy = {
'name': 'foo',
'comments': 'my comments',
'resource': 'bar',
'filters': [
{'type': 'baz', 'something': 'else'}
],
'actions': [
'suspend',
{'type': 'notify', 'violation_desc': 'vdesc'}
],
'mode': {'schedule': 'bar'}
}
expected = {
'name': 'foo',
'comments': 'my comments',
'resource': 'bar',
'filters': [
{'type': 'baz', 'something': 'else'}
],
'mode': {
'type': 'periodic',
'schedule': 'bar',
'tags': {'Component': 'foo'}
},
'actions': [
'suspend',
{
'type': 'notify',
'violation_desc': 'vdesc',
'questions_email': 'qemail',
'questions_slack': 'qslack',
'transport': {
'queue': 'q',
'type': 'sqs'
},
'to': [
'resource-owner',
'me@example.com'
]
},
{'Splunk': 'SQS'}
]
}
assert self.cls._apply_defaults(defaults, policy) == expected
def test_apply_defaults_tags(self):
defaults = {
'mode': {
'type': 'periodic',
'schedule': 'foo',
'tags': {'Project': 'cloud-custodian'}
},
'actions': [
{
'type': 'notify',
'questions_email': 'qemail',
'questions_slack': 'qslack',
'transport': {
'queue': 'q',
'type': 'sqs'
},
'to': [
'resource-owner',
'me@example.com'
]
}
]
}
policy = {
'name': 'foo',
'comments': 'my comments',
'resource': 'bar',
'filters': [
{'type': 'baz', 'something': 'else'}
],
'actions': [
'suspend',
{'type': 'notify', 'violation_desc': 'vdesc'}
]
}
expected = {
'name': 'foo',
'comments': 'my comments',
'resource': 'bar',
'filters': [
{'type': 'baz', 'something': 'else'}
],
'mode': {
'type': 'periodic',
'schedule': 'foo',
'tags': {'Component': 'foo', 'Project': 'cloud-custodian'}
},
'actions': [
'suspend',
{
'type': 'notify',
'violation_desc': 'vdesc',
'questions_email': 'qemail',
'questions_slack': 'qslack',
'transport': {
'queue': 'q',
'type': 'sqs'
},
'to': [
'resource-owner',
'me@example.com'
]
},
{'Splunk': 'SQS'}
]
}
assert self.cls._apply_defaults(defaults, policy) == expected
def test_apply_defaults_not_periodic(self):
defaults = {
'mode': {
'type': 'periodic',
'schedule': 'rate(1 day)',
'tags': {'foo': 'bar', 'baz': 'blam'}
},
'actions': [
{
'type': 'notify',
'questions_email': 'qemail',
'questions_slack': 'qslack',
'transport': {
'queue': 'q',
'type': 'sqs'
},
'to': [
'resource-owner',
'me@example.com'
]
}
]
}
policy = {
'name': 'foo',
'comments': 'my comments',
'resource': 'bar',
'filters': [
{'type': 'baz', 'something': 'else'}
],
'actions': [
'suspend',
{'type': 'notify', 'violation_desc': 'vdesc'}
],
'mode': {'type': 'bar', 'schedule': 'foo'},
}
expected = {
'name': 'foo',
'comments': 'my comments',
'resource': 'bar',
'filters': [
{'type': 'baz', 'something': 'else'}
],
'mode': {
'type': 'bar',
'schedule': 'foo'
},
'actions': [
'suspend',
{
'type': 'notify',
'violation_desc': 'vdesc',
'questions_email': 'qemail',
'questions_slack': 'qslack',
'transport': {
'queue': 'q',
'type': 'sqs'
},
'to': [
'resource-owner',
'me@example.com'
]
},
{'Splunk': 'SQS'}
]
}
assert self.cls._apply_defaults(defaults, policy) == expected
def test_apply_defaults_merge_call(self):
with patch('policygen.PolicyGen._merge_conf', autospec=True) as m:
m.return_value = {'mode': {'type': 'foo'}}
self.cls._apply_defaults({}, {'name': 'pname'})
assert m.mock_calls == [
call(self.cls, {}, {'name': 'pname'}, 'pname', [])
]
class TestMergeConf(object):
def setup(self):
self.cls = policygen.PolicyGen()
def test_merge_conf_missing(self):
update = {'foo': 'bar', 'baz': ['blam'], 'blarg': {'a': 'b'}}
assert self.cls._merge_conf({}, update, 'pname', []) == update
def test_merge_conf_string(self):
base = {'foo': 'bar', 'baz': 'blam'}
update = {'foo': 'newfoo'}
assert self.cls._merge_conf(base, update, 'pname', []) == {
'foo': 'newfoo', 'baz': 'blam'
}
def test_merge_conf_no_actions(self):
base = {'actions': [{'foo': 'bar'}, {'baz': 'blam'}], 'blam': 'blarg'}
update = {'foo': {'bar': 'newbar', 'baz': 'bazvalue'}}
expected = {
'foo': {
'bar': 'newbar',
'baz': 'bazvalue'
},
'blam': 'blarg'
}
assert self.cls._merge_conf(base, update, 'pname', []) == expected
def test_merge_conf_dict(self):
base = {'foo': {'bar': 'barvalue', 'blam': 'blamvalue'}}
update = {'foo': {'bar': 'newbar', 'baz': 'bazvalue'}}
expected = {
'foo': {
'bar': 'newbar',
'baz': 'bazvalue',
'blam': 'blamvalue'
}
}
assert self.cls._merge_conf(base, update, 'pname', []) == expected
def test_merge_conf_array(self):
base = {
'foo': 'bar',
'myarr': ['baz', 2, {'type': 'mytype'}]
}
update = {
'baz': 'bazvalue',
'myarr': ['one']
}
expected = {
'foo': 'bar',
'baz': 'bazvalue',
'myarr': ['foo', 'bar', 1]
}
with patch('policygen.PolicyGen._array_merge') as mock_am:
mock_am.return_value = ['foo', 'bar', 1]
res = self.cls._merge_conf(base, update, 'pname', [])
assert res == expected
assert mock_am.mock_calls == [call(
['baz', 2, {'type': 'mytype'}],
['one'],
'pname',
['myarr']
)]
class TestArrayMerge(object):
def setup(self):
self.cls = policygen.PolicyGen()
def test_not_dict(self):
base = ['one', 2, ['baz']]
update = [['baz'], 'three', 4]
expected = [['baz'], 'three', 4, 'one', 2]
assert self.cls._array_merge(base, update, 'pname', []) == expected
def test_dicts(self):
base = [
{'type': 'foo', 'bar': 'barvalue', 'extra': 'eval'},
{'type': 'bar', 'extra': 'eval'},
'blam',
'blarg'
]
update = [
{'type': 'foo', 'bar': 'barupdate', 'baz': 'blam'},
{'type': 'baz', 'bar': 'bazvalue'},
{'foo': 'bar'},
'blam'
]
expected = [
{'type': 'foo', 'bar': 'barupdate', 'extra': 'eval', 'baz': 'blam'},
{'type': 'baz', 'bar': 'bazvalue'},
{'foo': 'bar'},
'blam',
'blarg',
{'type': 'bar', 'extra': 'eval'}
]
assert self.cls._array_merge(base, update, 'pname', []) == expected
def test_no_add_notification(self):
# ensure that _array_merge() doesn't add a notify action to policies
# that don't have one
base = [
{'type': 'notify', 'to': ['foo', 'bar']}
]
update = [
'foo',
'bar',
{'type': 'baz', 'blam': 'blarg'}
]
assert self.cls._array_merge( base, update, 'pname', ['actions']) == [
'foo',
'bar',
{'type': 'baz', 'blam': 'blarg'}
]
def test_base_dict_no_type(self):
base = [{'foo': 'bar'}]
with pytest.raises(RuntimeError):
self.cls._array_merge(base, [], 'pname', [])
def test_base_multiple_type(self):
base = [
{'type': 'foo'},
{'type': 'foo'}
]
with pytest.raises(RuntimeError):
self.cls._array_merge(base, [], 'pname', [])
def test_base_not_array(self):
base = 'foo'
update = [1, 2]
with pytest.raises(RuntimeError):
self.cls._array_merge(base, update, 'pname', [])
class TestWriteFile(object):
def setup(self):
self.cls = policygen.PolicyGen()
def test_write(self):
with patch('policygen.open', mock_open(), create=True) as m_open:
self.cls._write_file('fpath', 'fcontent')
assert m_open.mock_calls == [
call('fpath', 'w'),
call().__enter__(),
call().write('fcontent'),
call().__exit__(None, None, None)
]
class TestRun(object):
def setup(self):
self.cls = policygen.PolicyGen()
def test_simple(self):
def se_apply_defaults(klass, defaults, policy):
return '%s+defaults' % policy
policies = {
'foo': 'bar',
'baz': 'blam',
'defaults': 'quux'
}
with patch.multiple(
'policygen.PolicyGen',
autospec=True,
_read_policies=DEFAULT,
_apply_defaults=DEFAULT,
_policy_rst=DEFAULT,
_write_file=DEFAULT,
_generate_cleanup_policies=DEFAULT,
_check_policies=DEFAULT
) as mocks:
mocks['_read_policies'].return_value = policies
mocks['_apply_defaults'].side_effect = se_apply_defaults
mocks['_policy_rst'].return_value = 'polMD'
mocks['_generate_cleanup_policies'].return_value = [
'cleanup1', 'cleanup2'
]
self.cls.run()
assert mocks['_read_policies'].mock_calls == [call(self.cls)]
assert mocks['_apply_defaults'].mock_calls == [
call(self.cls, 'quux', 'blam'),
call(self.cls, 'quux', 'bar'),
call(self.cls, 'quux', 'cleanup1'),
call(self.cls, 'quux', 'cleanup2')
]
assert mocks['_generate_cleanup_policies'].mock_calls == [
call(self.cls, ['blam+defaults', 'bar+defaults'])
]
assert mocks['_policy_rst'].mock_calls == [
call(self.cls, policies)
]
assert mocks['_write_file'].mock_calls == [
call(self.cls, 'custodian.yml', yaml.dump(
{'policies': [
'blam+defaults',
'bar+defaults',
'cleanup1+defaults',
'cleanup2+defaults'
]}
)),
call(self.cls, 'policies.rst', 'polMD')
]
assert mocks['_check_policies'].mock_calls == [
call(
self.cls,
[
'blam+defaults',
'bar+defaults',
'cleanup1+defaults',
'cleanup2+defaults'
]
)
]
class TestCheckPolicies(object):
def setup(self):
self.cls = policygen.PolicyGen()
def test_success(self, capsys):
policies = [
{'name': 'foo', 'foo': 'bar'},
{'name': 'baz', 'baz': 'blam'}
]
with patch.multiple(
'policygen.PolicyGen',
autospec=True,
_check_policy_marked_for_op_first=DEFAULT
) as mocks:
mocks['_check_policy_marked_for_op_first'].return_value = True
self.cls._check_policies(policies)
assert mocks['_check_policy_marked_for_op_first'].mock_calls == [
call(self.cls, policies[0]),
call(self.cls, policies[1])
]
expected_out = 'OK: All policies passed sanity/safety checks.'
out, err = capsys.readouterr()
assert err == ''
assert out.strip() == expected_out
def test_failure(self, capsys):
def se_strip_doc(func):
return func.name
policies = [
{'name': 'foo', 'foo': 'bar'},
{'name': 'baz', 'baz': 'blam'}
]
with patch.multiple(
'policygen.PolicyGen',
autospec=True,
_check_policy_marked_for_op_first=DEFAULT,
) as mocks:
with patch('policygen.strip_doc') as mock_sd:
for x in mocks:
setattr(mocks[x], 'name', x)
mocks['_check_policy_marked_for_op_first'].return_value = False
mock_sd.side_effect = se_strip_doc
with pytest.raises(SystemExit) as ex:
self.cls._check_policies(policies)
assert ex.value.args[0] == 1
assert mocks['_check_policy_marked_for_op_first'].mock_calls == [
call(self.cls, policies[0]),
call(self.cls, policies[1])
]
expected_out = "ERROR: Some policies failed sanity/safety checks:\n"
expected_out += "baz\n"
expected_out += "\t" + "_check_policy_marked_for_op_first\n"
expected_out += "foo\n"
expected_out += "\t_check_policy_marked_for_op_first\n"
out, err = capsys.readouterr()
out = out.encode('ascii')
assert err == ''
assert out == expected_out
class TestCheckPolicyMarkedForOpFirst(object):
def setup(self):
self.cls = policygen.PolicyGen()
def test_no_filters(self):
policy = {'name': 'foo', 'actions': ['mark']}
assert self.cls._check_policy_marked_for_op_first(policy) is True
def test_no_marked_for_op(self):
policy = {
'name': 'foo',
'actions': ['mark'],
'filters': [
'alive',
{'tag:foo': 'present'}
]
}
assert self.cls._check_policy_marked_for_op_first(policy) is True
def test_marked_for_op_first(self):
policy = {
'name': 'foo',
'actions': ['mark'],
'filters': [
{
'type': 'marked-for-op',
'tag': 'foo',
'op': 'bar'
},
'alive',
{'tag:foo': 'present'}
]
}
assert self.cls._check_policy_marked_for_op_first(policy) is True
def test_marked_for_op_not_first(self):
policy = {
'name': 'foo',
'actions': ['mark'],
'filters': [
'alive',
{'tag:foo': 'present'},
{
'type': 'marked-for-op',
'tag': 'foo',
'op': 'bar'
}
]
}
assert self.cls._check_policy_marked_for_op_first(policy) is False
def test_marked_for_op_nested(self):
policy = {
'name': 'foo',
'actions': ['mark'],
'filters': [
{
'or': [
{'tag:foo': 'present'},
{
'type': 'marked-for-op',
'tag': 'foo',
'op': 'bar'
},
'alive'
]
}
]
}
assert self.cls._check_policy_marked_for_op_first(policy) is False
class TestCheckPolicyMarkButNoTagFilter(object):
def setup(self):
self.cls = policygen.PolicyGen()
def test_no_filters(self):
policy = {'name': 'foo', 'actions': ['mark']}
assert self.cls._check_policy_mark_but_no_tag_filter(policy) is True
def test_no_actions(self):
policy = {'name': 'foo'}
assert self.cls._check_policy_mark_but_no_tag_filter(policy) is True
def test_no_mark_actions(self):
policy = {'name': 'foo', 'actions': ['stop']}
assert self.cls._check_policy_mark_but_no_tag_filter(policy) is True
def test_one_mark_action_ok(self):
policy = {
'name': 'foo',
'actions': [
{
'type': 'mark-for-op',
'tag': 'c7n-mytag',
'op': 'stop',
'message': 'foo-mark {op}@{action_date}',
'days': 7
}
],
'filters': [
{
'type': 'value',
'key': 'Instances',
'value_type': 'size',
'op': 'less-than',
'value': 1
},
{
'tag:c7n-mytag': 'absent'
}
]
}
assert self.cls._check_policy_mark_but_no_tag_filter(policy) is True
def test_two_mark_actions_ok(self):
policy = {
'name': 'foo',
'actions': [
{
'type': 'mark-for-op',
'tag': 'c7n-mytag',
'op': 'stop',
'message': 'foo-mark {op}@{action_date}',
'days': 7
},
'stop',
{
'type': 'mark-for-op',
'tag': 'c7n-foobar',
'op': 'delete',
'message': 'foobar-mark {op}@{action_date}',
'days': 14
}
],
'filters': [
{
'type': 'value',
'key': 'Instances',
'value_type': 'size',
'op': 'less-than',
'value': 1
},
{
'tag:c7n-mytag': 'absent'
},
{
'tag:c7n-foobar': 'absent'
}
]
}
assert self.cls._check_policy_mark_but_no_tag_filter(policy) is True
def test_one_mark_action_no_filter(self):
policy = {
'name': 'foo',
'actions': [
{
'type': 'mark-for-op',
'tag': 'c7n-mytag',
'op': 'stop',
'message': 'foo-mark {op}@{action_date}',
'days': 7
}
],
'filters': [
{
'tag:c7n-NOTmytag': 'absent'
},
{
'type': 'value',
'key': 'Instances',
'value_type': 'size',
'op': 'less-than',
'value': 1
}
]
}
assert self.cls._check_policy_mark_but_no_tag_filter(policy) is False
def test_two_mark_actions_one_filter(self):
policy = {
'name': 'foo',
'actions': [
{
'type': 'mark-for-op',
'tag': 'c7n-mytag',
'op': 'stop',
'message': 'foo-mark {op}@{action_date}',
'days': 7
},
'stop',
{
'type': 'mark-for-op',
'tag': 'c7n-foobar',
'op': 'delete',
'message': 'foobar-mark {op}@{action_date}',
'days': 14
}
],
'filters': [
{
'type': 'value',
'key': 'Instances',
'value_type': 'size',
'op': 'less-than',
'value': 1
},
{
'tag:c7n-NOTmytag': 'absent'
},
{
'tag:c7n-foobar': 'absent'
}
]
}
assert self.cls._check_policy_mark_but_no_tag_filter(policy) is False
def test_two_mark_actions_no_filters(self):
policy = {
'name': 'foo',
'actions': [
{
'type': 'mark-for-op',
'tag': 'c7n-mytag',
'op': 'stop',
'message': 'foo-mark {op}@{action_date}',
'days': 7
},
'stop',
{
'type': 'mark-for-op',
'tag': 'c7n-foobar',
'op': 'delete',
'message': 'foobar-mark {op}@{action_date}',
'days': 14
}
],
'filters': [
{
'type': 'value',
'key': 'Instances',
'value_type': 'size',
'op': 'less-than',
'value': 1
},
{
'tag:c7n-NOTmytag': 'absent'
}
]
}
assert self.cls._check_policy_mark_but_no_tag_filter(policy) is False
class TestGenerateCleanupPolicies(object):
def setup(self):
self.cls = policygen.PolicyGen()
def test_cleanup(self):
lcleanup = {
'name': 'c7n-cleanup-lambda',
'comment': 'Find and alert on orphaned c7n Lambda functions',
'resource': 'lambda',
'actions': [{
'type': 'notify',
'violation_desc': 'The following cloud-custodian Lambda '
'functions appear to be orphaned',
'action_desc': 'and should probably be deleted',
'subject': '[cloud-custodian {{ account }}] Orphaned '
'cloud-custodian Lambda funcs in {{ region }}',
'to': ['us@example.com']
}],
'filters': [
{'tag:Project': 'cloud-custodian'},
{'tag:Component': 'present'},
{
'type': 'value',
'key': 'tag:Component',
'op': 'ne',
'value': 'c7n-cleanup-lambda'
},
{
'type': 'value',
'key': 'tag:Component',
'op': 'ne',
'value': 'c7n-cleanup-cwe'
},
{
'type': 'value',
'key': 'tag:Component',
'op': 'ne',
'value': 'sqs_splunk_lambda'
},
{
'type': 'value',
'key': 'tag:Component',
'op': 'ne',
'value': 'foo'
},
{
'type': 'value',
'key': 'tag:Component',
'op': 'ne',
'value': 'bar'
},
{
'type': 'value',
'key': 'tag:Component',
'op': 'ne',
'value': 'baz'
}
]
}
cwecleanup = {
'name': 'c7n-cleanup-cwe',
'comment': 'Find and alert on orphaned c7n CloudWatch Events',
'resource': 'event-rule',
'actions': [{
'type': 'notify',
'violation_desc': 'The following cloud-custodian CloudWatch '
'Event rules appear to be orphaned',
'action_desc': 'and should probably be deleted',
'subject': '[cloud-custodian {{ account }}] Orphaned '
'cloud-custodian CW Event rules in {{ region }}',
'to': ['us@example.com']
}],
'filters': [
{
'type': 'value',
'key': 'Name',
'op': 'glob',
'value': 'custodian-*'
},
{
'type': 'value',
'key': 'Name',
'op': 'ne',
'value': 'custodian-c7n-cleanup-lambda'
},
{
'type': 'value',
'key': 'Name',
'op': 'ne',
'value': 'custodian-c7n-cleanup-cwe'
},
{
'type': 'value',
'key': 'tag:Component',
'op': 'ne',
'value': 'sqs_splunk_lambda'
},
{
'type': 'value',
'key': 'Name',
'op': 'ne',
'value': 'custodian-foo'
},
{
'type': 'value',
'key': 'Name',
'op': 'ne',
'value': 'custodian-bar'
},
{
'type': 'value',
'key': 'Name',
'op': 'ne',
'value': 'custodian-baz'
}
]
}
policies = [
{'mode': {'type': 'periodic'}, 'name': 'foo'},
{'name': 'bar'},
{'mode': {'type': 'periodic'}, 'name': 'baz'}
]
assert self.cls._generate_cleanup_policies(policies) == [
lcleanup, cwecleanup
]
class TestPolicyRst(object):
def setup(self):
self.cls = policygen.PolicyGen()
def test_rst_jenkins(self):
def se_comment(klass, policy):
return '%s-comment' % policy
policies = {
'foo': 'bar',
'baz': 'blam'
}
timestr = 'someTime'
gitlink = REPO_HTML + 'commit/' + 'abcd1234'
expected = "this page built by `custodian-config/foo 2 " \
"<https://jenkins/job/2>`_ from `abcd1234 <%s>`_ at %s\n\n" % (
gitlink, timestr
)
expected += "tableHere"
with patch('policygen.PolicyGen._policy_comment', autospec=True) as m:
m.side_effect = se_comment
with patch.dict(os.environ, {
'GIT_COMMIT': 'abcd1234',
'BUILD_NUMBER': '2',
'JOB_NAME': 'custodian-config/foo',
'BUILD_URL': 'https://jenkins/job/2'
}, clear=True):
with patch('policygen.timestr') as m_timestr:
with patch('policygen.tabulate') as m_tabulate:
m_tabulate.return_value = 'tableHere'
m_timestr.return_value = timestr
res = self.cls._policy_rst(policies)
assert res == expected
assert m_tabulate.mock_calls == [
call(
[
[
'`baz <%sblob/abcd1234/policies/baz.yml>`_' % REPO_HTML,
'blam-comment'
],
[
'`foo <%sblob/abcd1234/policies/foo.yml>`_' % REPO_HTML,
'bar-comment'
]
],
headers=['Policy Name', 'Description/Comment'],
tablefmt='grid'
)
]
def test_rst_local(self):
def se_comment(klass, policy):
return '%s-comment' % policy
policies = {
'foo': 'bar',
'baz': 'blam'
}
timestr = 'someTime'
gitlink = REPO_HTML + 'commit/' + 'abcd1234'
expected = "this page built locally from `abcd1234 <%s>`_ at %s" \
"\n\n" % (gitlink, timestr)
expected += "tableHere"
with patch('policygen.PolicyGen._policy_comment', autospec=True) as m:
m.side_effect = se_comment
with patch.dict(os.environ, {
'GIT_COMMIT': 'abcd1234'
}, clear=True):
with patch('policygen.timestr') as m_timestr:
with patch('policygen.tabulate') as m_tabulate:
m_tabulate.return_value = 'tableHere'
m_timestr.return_value = timestr
res = self.cls._policy_rst(policies)
assert res == expected
assert m_tabulate.mock_calls == [
call(
[
[
'`baz <%sblob/abcd1234/policies/baz.yml>`_' % REPO_HTML,
'blam-comment'
],
[
'`foo <%sblob/abcd1234/policies/foo.yml>`_' % REPO_HTML,
'bar-comment'
]
],
headers=['Policy Name', 'Description/Comment'],
tablefmt='grid'
)
]
class TestPolicyComment(object):
def setup(self):
self.cls = policygen.PolicyGen()
def test_comment(self):
policy = {
'comment': 'mycomment',
'comments': 'mycomments',
'description': 'mydescription'
}
assert self.cls._policy_comment(policy) == 'mycomment'
def test_comments(self):
policy = {
'comments': 'mycomments',
'description': 'mydescription'
}
assert self.cls._policy_comment(policy) == 'mycomments'
def test_description(self):
policy = {
'description': 'mydescription'
}
assert self.cls._policy_comment(policy) == 'mydescription'
def test_none(self):
policy = {}
assert self.cls._policy_comment(policy) == 'unknown'
class TestReadPolicies(object):
def setup(self):
self.cls = policygen.PolicyGen()
def test_read(self):
def se_read(klass, fpath):
name = fpath.split('/')[1].split('.')[0]
return {'file': fpath, 'name': name}
with patch('policygen.os.listdir', autospec=True) as mock_list:
with patch(
'policygen.PolicyGen._read_file_yaml', autospec=True
) as mock_read:
mock_list.return_value = [
'foo.yml',
'bar.yml',
'defaults.yml',
'README.md'
]
mock_read.side_effect = se_read
res = self.cls._read_policies()
assert res == {
'foo': {'file': 'policies/foo.yml', 'name': 'foo'},
'bar': {'file': 'policies/bar.yml', 'name': 'bar'},
'defaults': {'file': 'policies/defaults.yml', 'name': 'defaults'}
}
def test_read_bad_name(self):
def se_read(klass, fpath):
name = fpath.split('/')[1].split('.')[0]
if name == 'foo':
name = 'wrongName'
return {'file': fpath, 'name': name}
with patch('policygen.os.listdir', autospec=True) as mock_list:
with patch(
'policygen.PolicyGen._read_file_yaml', autospec=True
) as mock_read:
mock_list.return_value = [
'foo.yml',
'bar.yml',
'defaults.yml',
'README.md'
]
mock_read.side_effect = se_read
with pytest.raises(RuntimeError) as ex:
self.cls._read_policies()
assert ex.value.message == 'ERROR: Policy file foo.yml contains ' \
'policy with name "wrongName".'
class TestReadFileYaml(object):
def setup(self):
self.cls = policygen.PolicyGen()
def test_read(self):
m = mock_open(read_data="- foo\n- bar\n")
with patch('policygen.open', m, create=True) as m_open:
res = self.cls._read_file_yaml('/foo/bar.yml')
assert res == ['foo', 'bar']
assert m_open.mock_calls == [
call('/foo/bar.yml', 'r'),
call().__enter__(),
call().read(),
call().__exit__(None, None, None)
]
def test_read(self):
m = mock_open(read_data="- foo\n- bar\n")
with patch('policygen.open', m, create=True) as m_open:
res = self.cls._read_file_yaml('/foo/bar.yml')
assert res == ['foo', 'bar']
assert m_open.mock_calls == [
call('/foo/bar.yml', 'r'),
call().__enter__(),
call().read(),
call().__exit__(None, None, None)
]
def test_read_exception(self):
m = mock_open(read_data=" - foo:\n- bar")
with patch('policygen.open', m, create=True) as m_open:
with pytest.raises(Exception):
self.cls._read_file_yaml('/foo/bar.yml')
assert m_open.mock_calls == [
call('/foo/bar.yml', 'r'),
call().__enter__(),
call().read(),
call().__exit__(None, None, None)
]
errorscan.py
#!/usr/bin/env python
"""
Script to scan CloudWatch metrics and Dead Letter SQS queue for all
cloud-custodian lambda functions, and print info and logs and exit non-zero if
any failed or errored.
"""
import sys
import argparse
import logging
import boto3
from botocore.config import Config
import re
from time import time, sleep
from datetime import datetime, timedelta, tzinfo
from operator import itemgetter
import json
import os
FORMAT = "[%(asctime)s %(levelname)s] %(message)s"
logging.basicConfig(level=logging.WARNING, format=FORMAT)
logger = logging.getLogger()
# suppress boto3 internal logging below WARNING level
boto3_log = logging.getLogger("boto3")
boto3_log.setLevel(logging.WARNING)
boto3_log.propagate = True
# suppress botocore internal logging below WARNING level
botocore_log = logging.getLogger("botocore")
botocore_log.setLevel(logging.WARNING)
botocore_log.propagate = True
# Override max attempts for botocore retry configuration, to cope with
# throttling. This constant is used in two different places below...
BOTOCORE_MAX_ATTEMPTS = 10
def red(s):
"""
Return the given string (``s``) surrounded by the ANSI escape codes to
print it in red.
:param s: string to console-color red
:type s: str
:returns: s surrounded by ANSI color escapes for red text
:rtype: str
"""
return "\033[0;31m" + s + "\033[0m"
def green(s):
"""
Return the given string (``s``) surrounded by the ANSI escape codes to
print it in green.
:param s: string to console-color green
:type s: str
:returns: s surrounded by ANSI color escapes for green text
:rtype: str
"""
return "\033[0;32m" + s + "\033[0m"
class UTC(tzinfo):
"""UTC"""
def utcoffset(self, dt):
return timedelta(0)
def tzname(self, dt):
return "UTC"
def dst(self, dt):
return timedelta(0)
class LambdaHealthChecker(object):
"""Class for checking Lambda func health via CloudWatch"""
req_id_re = re.compile(
r'^(START|END|REPORT|\S+\s\S+)\s'
r'([0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}).*'
)
def __init__(self, func_name, logs=None, cw=None):
"""
Initialize LambdaHealthChecker
:param func_name: Lambda function name
:type func_name: str
:param logs: boto3 "logs" service client, or None to create new
:type logs: boto3.client
:param cw: boto3 "cloudwatch" Service Resource, or None to create new
:type cw: boto3.resource
"""
self._func_name = func_name
if logs is None:
# override default max_attempts from 5 to 10, for throttling
retry_conf = Config(retries={'max_attempts': BOTOCORE_MAX_ATTEMPTS})
self._logs = boto3.client('logs', config=retry_conf)
else:
self._logs = logs
if cw is None:
self._cw = boto3.resource('cloudwatch')
else:
self._cw = cw
def get_filtered_logs(
self, request_ids, interval=86400, group_name=None
):
"""
Get CloudWatch logs for the last ``interval`` seconds and return only
those entries with messages matching ``filter_re``.
:param request_ids: list of str request IDs to get logs for
:type request_ids: list
:param group_name: CloudWatch logs group name. If left at default of
``None``, defaults to ``/aws/lambda/{func_name}``.
:type group_name: str
:param interval: how far back in logs to look, in seconds
:type interval: int
:return: dict of request_id to list of log entry dicts
:rtype: dict
"""
logs = self.get_cloudwatch_logs(
interval=interval, group_name=group_name
)
if group_name is None:
group_name = '/aws/lambda/%s' % self._func_name
result = {}
matchcount = 0
for log in logs:
m = self.req_id_re.match(log['message'])
if m is None:
logger.debug(
'Event %s in group %s stream %s does not match '
'RequestId regex: %s', log['eventId'], group_name,
log['logStreamName'], log['message']
)
continue
req_id = m.group(2)
# logger.debug("RequestID: %s Message: %s", req_id, log['message'])
if req_id in request_ids:
log['logGroupName'] = group_name
if req_id not in result:
result[req_id] = []
result[req_id].append(log)
matchcount += 1
logger.debug(
'Filtered %d log messages to %d messages from %d invocations',
len(logs), matchcount, len(result)
)
return result
def get_cloudwatch_logs(self, interval=86400, group_name=None):
"""
Get CloudWatch logs for the last ``interval`` seconds. The log group
name defaults to ``/aws/lambda/{func_name}`` if left at the default of
None.
:param group_name: CloudWatch logs group name. If left at default of
``None``, defaults to ``/aws/lambda/{func_name}``.
:type group_name: str
:param interval: how far back in logs to look, in seconds
:type interval: int
:return: list of log entry dicts, sorted by timestamp
:rtype: list
"""
interval = interval * 1000 # milliseconds
now = int(time()) * 1000
cutoff = now - interval
if group_name is None:
group_name = '/aws/lambda/%s' % self._func_name
logger.debug('Finding streams in CW Log Group: %s', group_name)
paginator = self._logs.get_paginator('describe_log_streams')
stream_iterator = paginator.paginate(
logGroupName=group_name,
orderBy='LastEventTime',
descending=True
)
streams = []
try:
for resp in stream_iterator:
for stream in resp['logStreams']:
if stream.get('lastEventTimestamp', 0) < cutoff:
continue
streams.append(stream['logStreamName'])
except Exception as ex:
if hasattr(ex, 'response'):
emsg = ex.response.get('Error', {}).get('Code', 'unknown')
if emsg == 'ResourceNotFoundException':
logger.warning('CloudWatch Log group does not exist: %s',
group_name)
return []
raise
logger.debug('Found %d log streams with events in time span',
len(streams))
logs = []
for sname in streams:
logs.extend(self._get_cw_log_stream(
group_name,
sname,
cutoff,
now
))
return sorted(logs, key=itemgetter('timestamp'))
def _get_cw_log_stream(self, group_name, stream_name, start_ts, end_ts):
"""
Return all log messages from the specified stream at or after ``ts``.
:param group_name: CloudWatch log group name
:type group_name: str
:param stream_name: CloudWatch log stream name
:type stream_name: str
:param start_ts: timestamp in milliseconds to return logs after
:type start_ts: int
:param end_ts: timestamp in milliseconds to return logs before
:type end_ts: int
:return:
:rtype: list
"""
messages = []
logger.debug('Getting events from CloudWatch Logs Group %s stream %s',
group_name, stream_name)
paginator = self._logs.get_paginator('filter_log_events')
resp_iter = paginator.paginate(
logGroupName=group_name,
logStreamNames=[stream_name],
startTime=start_ts,
endTime=end_ts
)
for resp in resp_iter:
messages.extend(resp['events'])
logger.debug('Found %d messages in stream %s',
len(messages), stream_name)
return messages
def get_cloudwatch_metric_sums(self, interval=86400, period=86400):
"""
Return a dict of CloudWatch Metrics for this Lambda function, summed
over ``interval``. Keys are metric names ("Errors", "Throttles",
"Invocations") and values are sums of each ``period``-period datapoint,
for the past ``interval`` seconds.
For further information on these metrics, see:
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/
lam-metricscollected.html
:param interval: how many seconds of historical data to request
:type interval: int
:param period: the metric collection period to request from CloudWatch
:type period: int
:return: dict of metric name to sum for the last ``interval`` seconds
:rtype: dict
"""
res = {'Errors': 0.0, 'Throttles': 0.0, 'Invocations': 0.0}
now = datetime.utcnow().replace(tzinfo=UTC())
start = now - timedelta(seconds=interval)
logger.debug('Checking CloudWatch Metrics for Lambda function: %s',
self._func_name)
for m in self._cw.metrics.filter(
Namespace='AWS/Lambda',
Dimensions=[
{
'Name': 'FunctionName',
'Value': self._func_name
}
]
):
dims = _name_value_dict(m.dimensions)
# Lambda metrics are published twice, once with just
# FunctionName, and a second time with both FunctionName and
# Resource. Skip the duplicates that also have Resource dimension.
if dims.keys() != ['FunctionName']:
continue
stats = m.get_statistics(
Dimensions=[{'Name': 'FunctionName', 'Value': self._func_name}],
StartTime=start,
EndTime=now,
Period=period,
Statistics=['Sum']
)
val = sum([x['Sum'] for x in stats['Datapoints']])
res[m.metric_name] = val
logger.debug('Metrics for %s: %s', self._func_name, res)
return res
@staticmethod
def find_matching_func_names(filter, client=None):
"""
Return a list of all Lambda functions with names that either start
with ``filter`` (if ``filter`` is a string) or match ``filter`` (if
filter is a :py:class:`re.RegexObject`).
:param filter: lambda function name filter
:type filter: ``str`` or :py:class:`re.RegexObject`
:param client: boto3 Lambda client, or None to create new
:type client: boto3.client
:return: list of matching Lambda function names
:rtype: list
"""
if client is None:
client = boto3.client('lambda')
if isinstance(filter, type('')):
filter = re.compile('^' + re.escape(filter) + '.*')
logger.debug(
'Finding Lambda function names matching: %s', filter.pattern
)
matches = []
total = 0
paginator = client.get_paginator('list_functions')
for response in paginator.paginate():
for func in response['Functions']:
total += 1
if not filter.match(func['FunctionName']):
continue
matches.append(func['FunctionName'])
logger.debug('Matched %d of %d Lambda functions', len(matches), total)
return sorted(matches)
class CustodianErrorReporter(object):
"""Scan and report on CW Metrics/Logs errors for c7n lambdas"""
#: How far to look back in logs and metrics, in seconds
INTERVAL = 86400
#: Human-readable description of the interval
INVL_DESC = 'day'
#: What period to request CloudWatch metrics for
METRIC_PERIOD = 86400
#: Amount of time (float seconds) to sleep between checking each function,
#: to try to avoid API rate limiting.
INTER_FUNC_SLEEP = 3.0
def __init__(self, dlq_arn):
self._dlq_arn = dlq_arn
# override default max_attempts from 5 to 10, for throttling
retry_conf = Config(retries={'max_attempts': BOTOCORE_MAX_ATTEMPTS})
self._logs = boto3.client('logs', config=retry_conf)
self._cw = boto3.resource('cloudwatch')
self._lambda = boto3.client('lambda')
self._sqs = boto3.client('sqs')
self._now = datetime.now()
self._start = self._now - timedelta(seconds=self.INTERVAL)
self._failed_request_ids = {} # set by _get_sqs_dlq()
self._sqs_rcpts = [] # set by _get_sqs_dlq()
def run(self):
""" collect and report on all cloud-custodian Lambda errors """
print(
'Searching cloud-custodian Lambda functions for failed invocations'
)
lambda_names = LambdaHealthChecker.find_matching_func_names(
re.compile(r'^(custodian-|cloud-custodian-).*')
)
logger.debug('Custodian Lambda functions: %s', lambda_names)
errors = False
self._get_sqs_dlq()
logger.debug(
'%d failed Lambda invocations: %s',
len(self._failed_request_ids), self._failed_request_ids.keys()
)
for fname in lambda_names:
if not self._check_function(fname):
logger.info(
'_check_function returned False (NOT HEALTHY) for: %s',
fname
)
errors = True
logger.debug(
'Sleeping %s seconds before checking next function',
self.INTER_FUNC_SLEEP
)
sleep(self.INTER_FUNC_SLEEP)
self._ack_sqs()
req_ids = [
i for i in self._failed_request_ids
if self._failed_request_ids[i] is None
]
if len(req_ids) > 0:
print(
"\n\n" +
red('ERROR: %d failed Lambda RequestIDs could not be tied '
'to their function names: %s' % (len(req_ids), req_ids))
+ "\n\n"
)
if errors:
print('Some lambda functions had errors in the last '
'%s' % self.INVL_DESC)
raise SystemExit(1)
print('No Lambda functions had errors in the last ' + self.INVL_DESC)
def _get_sqs_dlq(self):
"""
Pull all messages from the SQS Dead Letter Queue. Add the failed Lambda
RequestIDs to `self._failed_request_ids` and the SQS Reciept Handles
to `self._sqs_rcpts`.
"""
count = 0
msgs = [None]
logger.info('Polling SQS queue: %s', self._dlq_arn)
while len(msgs) > 0:
response = self._sqs.receive_message(
QueueUrl=self._dlq_arn,
WaitTimeSeconds=20,
MaxNumberOfMessages=10,
MessageAttributeNames=['RequestID', 'ErrorMessage'],
AttributeNames=['SentTimestamp']
)
msgs = response.get('Messages', [])
logger.debug('%d SQS Messages received from one poll', len(msgs))
for m in msgs:
count += 1
self._failed_request_ids[
m['MessageAttributes']['RequestID']['StringValue']] = None
self._sqs_rcpts.append(m['ReceiptHandle'])
logger.info('Received %d SQS messages in total', count)
logger.debug('SQS Message Receipt Handles: %s', self._sqs_rcpts)
def _ack_sqs(self):
"""
Delete (ack) all SQS messages in `self._sqs_rcpts`.
"""
for rh in self._sqs_rcpts:
self._sqs.delete_message(
QueueUrl=self._dlq_arn,
ReceiptHandle=rh
)
def _check_function(self, func_name):
"""
Check health of one Lambda function. Print information on it to STDOUT.
Return True for healthy, False if errors/failures.
:param func_name: Lambda function name to check
:type func_name: str
:return: whether the function had errors/failures
:rtype: bool
"""
c = LambdaHealthChecker(func_name, logs=self._logs, cw=self._cw)
req_ids = [
i for i in self._failed_request_ids
if self._failed_request_ids[i] is None
]
logs = c.get_filtered_logs(req_ids)
metrics = c.get_cloudwatch_metric_sums()
msg = []
if metrics['Invocations'] > 0:
throttle_pct = (metrics['Throttles'] / metrics['Invocations']) * 100
error_pct = (metrics['Errors'] / metrics['Invocations']) * 100
else:
throttle_pct = 0
error_pct = 0
if error_pct > 50:
msg.append('Lambda Function Errors: %s%% (%d of %d invocations)' % (
error_pct,
metrics['Errors'],
metrics['Invocations']
))
if throttle_pct > 50:
msg.append(
'Lambda Function Throttles: %s%% (%d of %d invocations)' % (
throttle_pct,
metrics['Throttles'],
metrics['Invocations']
)
)
if len(logs) < 1 and len(msg) == 0:
print(green('%s: OK\n' % func_name))
return True
print(red('%s: ERRORS' % func_name))
for m in msg:
print("\t%s" % red(m))
if len(logs) < 1:
return True
print("\n\tLogs For Failed Invocations:\n")
for req_id in logs.keys():
events = logs[req_id]
self._failed_request_ids[req_id] = func_name
print("\t" + red('RequestID=%s logGroupName=%s logStreamName=%s' % (
req_id, events[0]['logGroupName'], events[0]['logStreamName']
)))
for e in events:
print("\n".join([
"\t\t%s" % l.replace("\t", ' ')
for l in e['message'].split("\n")
if l.strip() != ''
]))
print('')
return False
def _name_value_dict(l):
"""
Given a list (``l``) containing dicts with ``Name`` and ``Value`` keys,
return a single dict of Name -> Value.
"""
res = {}
for item in l:
res[item['Name']] = item['Value']
return res
def parse_args(argv):
p = argparse.ArgumentParser(description='Report on c7n lambda errors')
p.add_argument('-v', '--verbose', dest='verbose', action='count', default=0,
help='verbose output. specify twice for debug-level output.')
p.add_argument('DLQ_ARN', action='store', type=str,
help='ARN to SQS Dead Letter Queue for all Lambda funcs')
args = p.parse_args(argv)
return args
def set_log_info():
"""set logger level to INFO"""
set_log_level_format(logging.INFO,
'%(asctime)s %(levelname)s:%(name)s:%(message)s')
def set_log_debug():
"""set logger level to DEBUG, and debug-level output format"""
set_log_level_format(
logging.DEBUG,
"%(asctime)s [%(levelname)s %(filename)s:%(lineno)s - "
"%(name)s.%(funcName)s() ] %(message)s"
)
def set_log_level_format(level, format):
"""
Set logger level and format.
:param level: logging level; see the :py:mod:`logging` constants.
:type level: int
:param format: logging formatter format string
:type format: str
"""
formatter = logging.Formatter(fmt=format)
logger.handlers[0].setFormatter(formatter)
logger.setLevel(level)
if __name__ == "__main__":
args = parse_args(sys.argv[1:])
# set logging level
if args.verbose > 1:
set_log_debug()
elif args.verbose == 1:
set_log_info()
CustodianErrorReporter(args.DLQ_ARN).run()
Comments
comments powered by Disqus